
05 Moving to Modern Data Infrastructure
How we built a data stack without a data team


Localazy has been running for years now, and our data setup grew the way most startups’ do. Organically, chaotically, and eventually painfully.
It starts with Google Tag Manager because it’s free. Then you add analytics tools as needs arise, build point-to-point connections to solve immediate problems. Before you notice, you’re making decisions based on conflicting numbers nobody trusts.
The standard advice assumes you have the time and resources to do it right from the start. We didn’t and from my experience most startups don’t either.
What the Pain Actually Looked Like
I could describe this abstractly, but the specifics matter.
At first, our marketing team couldn’t measure customer acquisition cost by channel and rely on conversion data. Real money was going to ads with low confidence in what was working. Attribution models broke because customer journeys were split across disconnected systems.
Product decisions that should normally take hours took days. Every question required manual data collection from multiple places, followed by reconciliation work when the numbers didn’t add up. As a result, we couldn’t trust the insights, so we second-guessed everything.
Sales and customer success spent roughly eight hours weekly just collecting payment data. Revenue in the CRM didn’t match the revenue numbers in other systems. Customer communications couldn’t be realiably automated at critical touchpoints because our systems didn’t talk to each other.
We’d deliberately avoided premature optimization early on. Looking back, that was probably the right call. Building infrastructure before you know what you need is its own kind of waste. But the technical debt compounded faster than anyone expected.
The Question We Were Trying to Answer
When it comes to data, everyone talks about tech stacks. Which warehouse should we choose? Which transformation layer? Which BI tool works the best?
I can understand why, it’s concrete. You can compare feature lists or read blog posts from companies that seem to have figured it out.
But choosing a tech stack wasn’t the real problem. The question we were asking ourselves was:
How do you build something reliable and cost-effective that one person can maintain, that delivers value quickly, and that doesn’t lock you into decisions you’ll regret in two years?
Those are constraints that pull in different directions.
The Constraints That Shaped Everything
Technical requirements were straightforward: handle around 10 million events monthly with room to grow, unify streaming and batch data, don’t lose data during migration, and design for component replacement.
Business requirements were harder. And honestly more important.
One person would maintain this. Not a team. One engineer, full-time. If the architecture required a dedicated data team, we couldn’t afford it and it wouldn’t happen.
We needed a single source of truth. The whole point was eliminating conflicting metrics that eroded trust. Two dashboards showing different numbers is worse than no dashboard.
Teams needed to answer their own questions. If every analytics request required engineering involvement, we’d move the bottleneck instead of eliminating it.
And we needed to see value in weeks, not quarters. Nobody was going to approve a six-month project that promised benefits eventually. We had to show results quickly or lose support.
We were terrified of building something we couldn’t maintain, or scaling for problems we didn’t have yet, or getting locked into choices that felt right at the time but would haunt us later. So I optimized ruthlessly against those specific fears.
What We Built
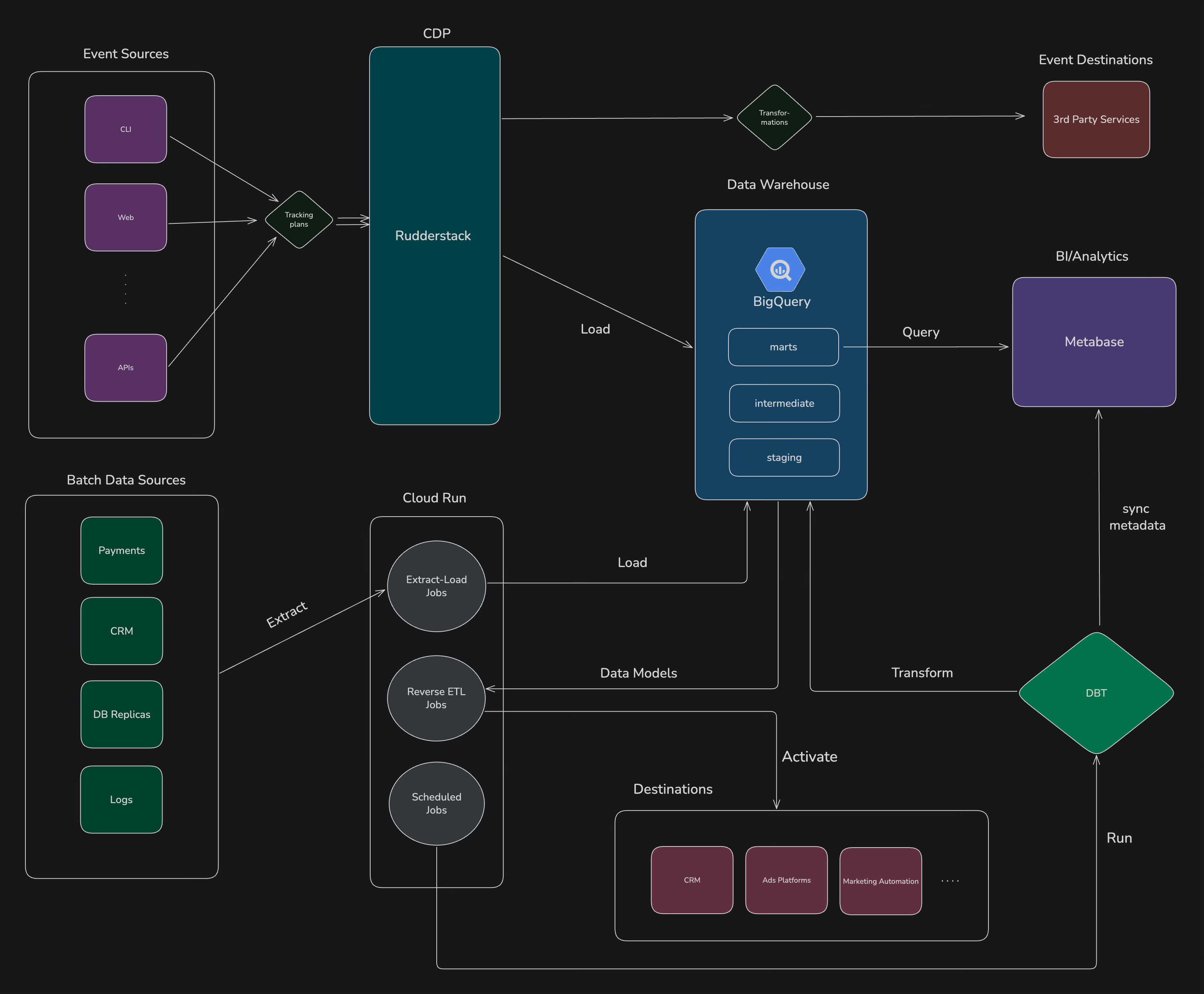
RudderStack handles data ingestion. Streaming through client and server SDKs, consent management, tracking plan enforcement, plus simple batch processing. It handles both real-time events and scheduled imports, which simplified our architecture significantly.
BigQuery became the single source of truth. Columnar storage, SQL interface, handles streaming and batch loads. Everything flows there. One place to look for data.
dbt Core runs the transformation layer. Git-versioned data models, automated testing, CI/CD, documentation. We implemented what’s called a medallion architecture: raw data lands in staging, business logic lives in intermediate layers, final models serve as marts. Three environments: development, staging, production.
Metabase provides exploration and self-service dashboards.
Python jobs on Cloud Run handle reverse ETL, syncing enriched data back to CRM and activation tools.
We didn’t use a fancy orchestration platform. Simple scheduled jobs worked. We’ll add orchestration when complexity demands it, not before.
The architecture is boring. That’s the point. Boring is maintainable.
How We Rolled It Out
We took a phased approach from day one. Trying to build everything at once is the fastest way to sink a data project as scope expands, deadlines slide, and trust collapses.
First two weeks: fix attribution immediately. We replaced existing tracking with RudderStack SDKs, configured direct streaming to advertising platforms, and established BigQuery as the collection point for historical analysis. Marketing can suddenly trust their attribution data. Campaign optimization confidence returned. Concrete win, fast.
Next four weeks: democratize data access. Implemented dbt with three-tier architecture, deployed automated quality tests at each layer, connected Metabase for self-service. Most analytics questions stopped requiring engineering involvement. Product managers could answer their own questions.
Final six weeks: unified customer view and full workflow automation. Connected data from database replicas and remaining third-party sources, built reverse ETL jobs, and implemented complete customer-journey models. Customer communication can now be automated based on behaviour, and it’s finally possible to combine product-usage events, production data, and customer feedback in one place.
Each phase delivered value and we didn’t have to wait months to prove the investment made sense.
What Could Go Wrong
Before kicking off the project, we spent time some mapping out the major ways the project could fail. The goal wasn’t to predict every scenario but to understand the most likely risks and prepare for them in a practical way.
Vendor lock-in was near the top of the list. To keep our options open, we built dbt models in standard SQL and chose RudderStack because it already supports a broad set of destinations. If we ever need to move part of the stack, the effort is realistic.
We also considered the risk of relying too heavily on a single person. To prevent that, all infrastructure lives in Git, the documentation is enforced and generated via CI, and the tooling is consistent across the team. Someone may know the system better than others, but no one is irreplaceable and everything is transparent.
Data quality could have easily undermined the entire effort. To keep trust high, validation happens at several points: schema checks during ingestion, automated tests in dbt, and basic monitoring checks that surface unusual patterns before they spread.
The risks remain, but they no longer threaten the project. They are visible, controlled, and easy to respond to.
How Much It Costs
Total infrastructure cost sits at roughly $1,700 per month, covering BigQuery, RudderStack, Cloud Run, and Metabase hosting. It’s a useful reminder that a functional, reliable data stack doesn’t need a six-figure budget.
About three-quarters of analytics questions are now answered without involving engineering. When a new question comes up, developers create a reusable model, and it becomes part of the toolkit for future work. Product, marketing, and sales teams can run their own queries, which has pushed decision-making speed way up. Work that once took days is resolved in a few hours.
The entire system is maintained by a single developer. There’s no data team, no dedicated analysts, just one engineer who can handle it alongside other responsibilities.
What’s Still Missing
Naturally, the data work is never done. Data infrastructure evolves with business needs, and pretending otherwise would be dishonest.
Job orchestration will become important as the pipelines grow more complex. At some point you’ll need to bring in a tool like Airflow or Dagster to manage dependencies and scheduling. For now, a set of straightforward scheduled jobs is enough.
Data quality monitoring also needs future improvement. More test coverage. Better freshness. Smaller jobs running more frequently.
Data security requires ongoing attention. Column-level access control, PII masking within BigQuery, reduced reliance on broad access policies.
Data lineage will become critical as more people use the system. Tracking dependencies reduces the risk of breaking downstream consumers when making changes.
But we’re not building these yet. We’ll build them when they become real problems, not before. Premature optimization is what got us into trouble in the past.
What I’d Tell Someone Starting This
Begin with something small and concrete. Solve a real problem and show progress within a few weeks. Early wins create momentum.
I’ve seen the team stall because they waited for perfect conditions: the ideal budget, the ideal team, the ideal architecture. Those conditions never arrive. Forward movement matters more than perfection.
Keep your data warehouse central. Use boring technology. Build in small phases. Deliver incremental value constantly.
The point isn’t to create a bulletproof system. The point is to help the company make decisions faster and with more confidence. Everything else is distraction.
We intentionally avoided premature optimization for a long time, and that choice created debt. Clearing it didn’t require a large team or a massive redesign. It only required a clear understanding of constraints, a phased plan, and a commitment to delivering value at every step.
That’s the real work. It doesn’t make for exciting conference talks, but it ships.